ReCal2 (“Reliability Calculator for 2 coders”) is an online utility that computes intercoder/interrater reliability coefficients for nominal data coded by two coders. (Versions for 3 or more coders working on nominal data and for any number of coders working on ordinal, interval, and ratio data are also available.) Here is a brief feature list:
- Calculates four of the most popular reliability coefficients for nominal data: percent agreement, Scott’s Pi, Cohen’s Kappa, and Krippendorff’s Alpha.
- Can calculate reliability for multiple variables at a time
- Accepts any range of possible variable values
- Results should be valid for nominal data coded by two coders (other uses are not endorsed, and accurate results are not guaranteed in any case — trust but verify!)
If you have used ReCal2 before, you may submit your data file for calculation via the form below. If you are a first-time user, please read the documentation first. (Note: failure to format data files properly may produce incorrect results!) You should also read ReCal’s very short license agreement before use.
- Data should be nominal
- Data for each variable should represent two coders’ judgments on the same units of analysis
- All codes must be represented numerically
- Input file must be formatted properly
- If you are calculating reliability for multiple variables at once, all variables must contain the same number of units of analysis (see below)
To format your data for ReCal2 analysis, follow these instructions:
- For each variable, make sure that each of your content analysis code values is represented by a unique number. E.g. 0 = absent, 1 = present, 99 = N/A. Your file must contain no characters other than numeric digits—no letters, no dashes, no decimal points, only digits.
- In Excel, SPSS, or another spreadsheet-like program, create a new file.
- Into the first two columns of your new file, enter the first and second coder’s data respectively, one unit of analysis per row, ensuring that each row represents the same unit of analysis. If you wish to calculate reliability for multiple variables, insert the second data pair into the third and fourth columns, the third pair into the fifth and sixth, etc. Because ReCal2 requires paired data for each variable, the number of columns in each data file submitted to it must be even. The screenshot below shows a file containing three variables, each with a corresponding pair of code data—A-B, C-D, and E-F.
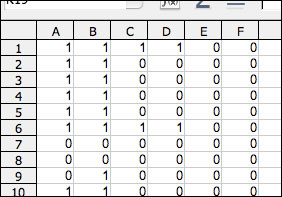
- Header information may be included in the first row of the file. If ReCal detects any letters on this row, it will discard the entire row and begin its analysis on the second row.
- There should be no missing data; ReCal2 will generate an error otherwise.
- If you are calculating reliability for multiple variables at once, all variables must contain the same number of units of analysis (i.e. all variables must end on the same row in your spreadsheet). If you need to calculate reliabilities for variables with different numbers of units of analysis, they must be entered into ReCal2 separately.
- Save this file in comma-Separated values (.csv), semicolon-separated values (also .csv), or tab-separated values format (.tsv)—simply changing the file extension to “.csv” or “.tsv” will not work; the file needs to be “saved as” CSV in whatever spreadsheet or stat program you’re using—and choose “comma” as the column or field delimiter (if applicable). Click through any warning messages that may pop up. The file should have a “.csv” or “.tsv” extension. Your file is now ready for analysis; use the file selection box above to locate it on your hard drive.
- Here is the full example file from which the screenshot above was taken. It contains three variables across six columns (two columns per variable) and 20 units of analysis. In a spreadsheet program it will look like a normal spreadsheet, but a web browser or text editor will display it as a series of comma-separated numbers.
If you’re having trouble getting ReCal2 to work with your data, first check the FAQ/troubleshooting page, and if you don’t find the answer to your question there, send me an email. Feel free also to leave any general questions or comments regarding ReCal2 below in comments.
One word. Awesome! This program gets the job done. Good work and keep bring it.
Hi, I have found this tool extremely useful – thanks very much!
A question though: you advise double checking the results which I have done for a few variables using SPSS. Using the Cohen’s Kappa test as an example, for many variables the results come out exactly the same as produced by ReCal. However, there have been a few instances where SPSS says that Kappa can’t be calculated because it ‘requires a 2-way table in which the values of the first variable match the second’. However, ReCal has produced me a Kappa value. Has anyone come across this before and advise if I’m doing something wrong, either in SPSS or in ReCal? Thanks.
Congratulations! You have (re-)discovered an error in SPSS. It occurs when one coder uses at least one category/variable value that the other doesn’t. But there is no algebraic reason kappa can’t be calculated in this situation. Apparently there used to be a macro available on the SPSS website that would do so that is no longer available; see this thread. Also, the irr package in R will calculate kappa for this kind of data with no errors, and that was written by Real Statisticians. So the ReCal value is correct, and you can double-check it in irr if you wish.
I just would like to say thank you!
It was like magic that solves unsolved problem.
Thank you! This tool is very easy to use, a PhD student’s dream!!!
i am testing intercoder reliability on 15 variables
most of the variables will be coded as 0 or 1
however 2 of the variables have 3 possible answers coded as 1 or 2 or 3
can these latter 2 variables be tested in the same way?
thanks!
Hi Deen,
Thanks for making this calculator! I have the same question as Maria, because my variable is nominal, but has more than two options (Nominal does not necessarily mean binary/dichotomous). Does ReCal2 work with nominal variables that can have more than 2 options?
Thanks in advance for your response, Sytske
I have the same question as Maria and .
Does ReCal2 work with nominal variables that can have more than 2 options?
very good maybe
Hello. Thank you for very much for this useful tool.
I am a little bit confused though, and would really appreciate it if someone can confirm that I used this correctly.
Two coders categorized 90 items into 5 categories: 1, 2, 3, 4, or 5.
So, column 1 has all the categorizations of coder 1. And column 2 has all the categorizations of coder 2.
Am I doing it right?
Can you tell me what the confidence interval is for ReCal2?
Wow, this is so much easier than getting Krippendorff’s macro working in SPSS (Hayes, A. F., & Krippendorff, K. (2007). Answering the Call for a Standard Reliability Measure for Coding Data. Communication Methods and Measures, 1(1), 77-89.)
Wish I had come a across your tool before. Thanks for building and sharing it!
I have more around 15 different attributes for one variable. It’s an explorative news content analysis!
Was wondering whether there is any limitation on the number of attributes. I do not have 0 value and it is only 1-15.
Also, I hope I can enter 1-7 attributes for first pair of columns and 1-15 attributes for next pair of columns for the two different variables?
Thanks a lot. This is a great device!
I was wondering if you can help me,
I have:
13 variables
224 participants
2 coders
However, coders can code `1` (i.e., present) across all 13 variables.
This means that Assumption 1 of Cohen`s Kappa is violated.
What do I do…I would appreciate any help. Thank you.
—
Assumption #1: The response (e.g., judgement) that is made by your two raters is measured on a nominal scale (i.e., either an ordinalor nominal variable) and the categories need to be mutually exclusive. For example, the two raters could be assessing whether a patient’s mole was “normal” or “suspicious” (i.e., two categories); whether the quality of service provided by a customer service agent was “above average”, “average” or “below average” (i.e., three categories); or whether a person’s activity level should be considered “sedentary”, “low”, “medium” or “high” (i.e., four categories). In addition, the categories being assessed by the two raters should be “mutually exclusive”, which means that no categories overlap (e.g., a rater could only consider a patient’s mole to be normal OR suspicious; the mole cannot be normal and suspicious at the same time).
https://statistics.laerd.com/spss-tutorials/cohens-kappa-in-spss-statistics.php
This is absolutely perfect! Thanks to much for creating this and making it available!
what if some of the questions are ordinal, some nominal and some ratio? what do I do?
How I should make a citation of your recal2?
I have the same question. How to I cite ?
Can you please tell me what is the confidence interval of Recal2?
Hello! this tool is amazing, thanks a lot! I was wondering… In some papers, I have noticed that authors just write one number for the Kappa analysis, although this tool generates one Kappa value for each variable. How can I get the overall Kappa value for the entire analysis? is it just an average from all of the values? thanks a lot in advance
Hi.
Does ReCal2 work with nominal variables that can have more than 2 options?
thanks
Hello,
please someone help me to calcul intercoder reliability.
Thanks
I have some data and i want to calculate the intercoder reliability. Can someone help me in this?
Some i have attached to you Prof Deen for assistance